
Building VC Fund AI Operating System
Here's what I've been building and why I think every company should be doing the same.

Latest AI agentic developments made it clear: any piece of work I’ll do before setting up my agentic rails risk of being inaccessible by agent, because even progression of thought is important. All the small research inputs I gather into the finalized thesis need to be able to be revisit, update and rethought. So couple weeks ago I’ve embarked on a journey of setting up an AI OS for the fund and I think you should do the same.
The bigger point first
I genuinely believe that every company being started today should be built on AI rails from day one. Not as an add-on. Not as a “we’ll integrate AI later” roadmap item. From the foundation.
The reason is simple: quality of the foundational models and their agency e.g. an ability to not just answer a question but iterate on a specific task using the context ****just broke some invisible threshold of being a decent employee.
A simple test here: connect Claude Cowork, or Codex to all the tools you use and run a prompt: “Make an audit of everything you have an access to. My role is X, try to make sense of everything I do and how you can help me, save results to local context”
And I’m not all that unicorns and butterflies futurist about AI replacing entire teams or so. I take a stance of organizations even keeping the same roles like engineering, research, marketing etc and maybe even the same people, but every person will be using agents to automate their individual tasks, validate/correct and be more productive in multiples, not just in percentage.
For every founder and a manager that poses the task of building their organization and toolset in a way that enables employees to use agents. It’s a real responsibility as on the organizational level these orgs will become more competitive to those that are not enabling their workforce.
While building AI enabled work environment is a responsibility of a founder, becoming AI native is a responsibility of every employee for the same reason: otherwise you will be outcompeted by your peers.
And, sadly, not everyone is able to learn and rebuild into the new identity so I suggest hiring only AI native people who have already upgraded themselves.
Designing the system
Here are several key principles for the system I used:
AI Availability
Every part of the stack should be available for AI, preferably without Browser interaction in between. This is the core of how you should operate. Even if you don’t enable AI now, the data should be structured, documented and available
Composability with existing tools.
We’re trying to keep most of the tools as they are: knowledge databases, communication channels, spreadsheets. They’re all amazing and allow collaboration and data representation, you don’t really want to just chat with AI all the time. If AI isn’t doing great you should be able to go and manually do your work
Flexibility and interchangeability
The AI world will evolve, some models and tools are better than others. You want to be able to change model, tool, context without too much work
Simplicity
In a bigger org you can and you should put a special team maintaining your org wide AI tools, but to begin with it shouldn’t be cumbersome as it will be a bottleneck for everyone.
Exact tool stack I use
Building this OS is mostly configuring existing apps vs building something completely new:
1 - Local folder
This is where The Context lives. You can and probably should have a canonical version of this folder maintained at your company level for everyone to download and use. It’s the base for any agentic work today and you can use this folder with Cowork/Codex/OpenClaw.
The first file is a 250-line master context document — the full company DNA. Mission, Philosophy, Values, Launch Goals, Thesis (liquid and venture), all 8 Notion database schemas with their relationships, portfolio data, current critical path. Claude loads both files and becomes something that functions less like a chatbot and more like a co-GP who remembers everything.
When I say “X” it knows I mean a potential anchor LP. When I say “CFM” it knows that’s my law firm. It knows my CRM pipeline stages, my thesis themes, my deal evaluation criteria. The context is the product.
Cool part that you can effectively steer the entire company by updating the canonical folder. Imagine your employee receives his daily brief every time with explanation how his tasks are connected to the overall company objectives!
The second is called CLAUDE.md. About 200 lines. Every time I start a session with Claude, it loads automatically. It contains who I am, how my fund works, every person I work with and their roles, internal jargon and acronyms, which tools live where, and — this is the part people find funny — instructions about how my brain works.
I have ADHD tendencies. I procrastinate on big ambiguous tasks. So I literally wrote instructions telling Claude: break big tasks into small steps, never present a wall of work, notice when I’m yak-shaving and redirect me.
Yes, I taught my AI how to manage me. And it works.
2 - Notion as the global knowledge database
I’ve picked it because frankly I love Notion as a default knowledge database for a company regardless of an AI. Also because the team gets AI and built an amazing MCP that can access tables and their specific views and operate over them. And it replaces Granola by taking and keeping all the meeting notes.
Everything is a database: instead of following mostly page based structure I use databases everywhere: Marketing output table, CRM table, Dealflow table, Research Table - this is a structured AND migratable way of organizing. Table entries can be effectively Tagged in columns so that model can access the high level data without going to the content itself.
On top of that Notion has already have a beta version of Agents configurable inside with various triggers.
3 - Obsidian
I’m a big fan of Outliner apps, started way ago with Workflowy then migrated to Dynalist, turns out Obsididian is created by the same team as Dynalist so it makes sense. I’ve tried to migrate to Obsidian multiple times but now the time has come. This one serves as my personal scratchpad and I love it, and since it’s all based on .md files AI works greatly with it.
4 - Superhuman, Notion Calendar, Figma, Slack, Telegram, Airtable
Nothing specific here, just a great set of tools each having an MCP server. I use this one for Telegram https://github.com/chaindead/telegram-mcp
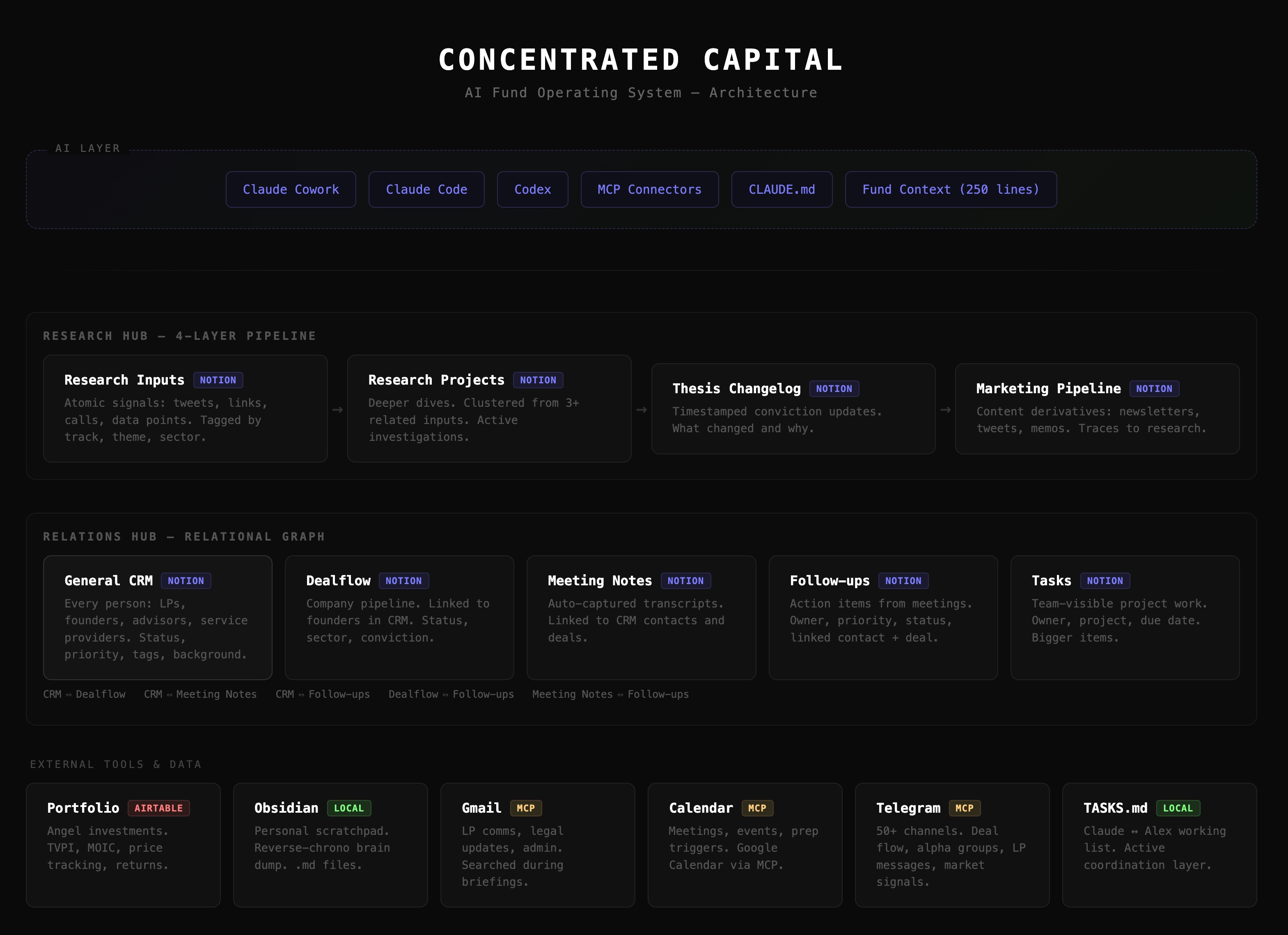
Core fund systems, all connected
The fund OS has three big parts, each built on interconnected Notion databases with shared taxonomy.
Research
This is a four-layer pipeline: Research Inputs (atomic signals — a tweet, a Dune query, a founder call note) then Research Projects (deeper dives) then Crystalized Thesis and Changelog (timestamped conviction updates) then Marketing Output Pipeline (content derivatives). Every signal gets tagged with track, thesis theme, sector, source. When I ask Claude “what’s our current thinking on CEX unbundling?” it traverses all four layers.
Relations
One CRM database where every person lives — LP, founder, advisor, service provider. Linked to Dealflow (companies), Meeting Notes (transcripts from calls), Tasks, and Follow-ups. It’s a relational graph that Claude can navigate. “When did I last talk to Mike?” — it checks CRM, pulls the meeting note, surfaces the follow-ups. All connected.
Content
Content isn’t a separate workstream — it’s a derivative of research. Every newsletter, deck update, LP memo traces back to underlying thesis work through the Marketing Output Pipeline. When it’s time to write, I’m never starting from blank. Claude pulls recent signals, references active research, drafts something grounded in real conviction changes.
What a day looks like
I ask for a /briefing. Claude scans nine sources simultaneously — Telegram messages, Gmail inbox, today’s calendar, Notion CRM contacts needing follow-up, overdue follow-ups, open tasks, dealflow changes, our shared TASKS.md working list, and Airtable portfolio updates.
It synthesizes into a single prioritized output. What needs action today. What’s coming this week. What’s FYI.
After a /call, I say “update the CRM.” Claude pulls the meeting transcript from Notion, extracts key info, updates the contact record, creates follow-up items, links everything together.
I constantly pour /research Inputs into the database of everything relevant to my thesis and how the space evolves. Claude take the first go on each of them. Later we organize this into groups and come with a bigger research points that later become materials.
When I’m stuck on a big task — which happens more than I’d like — Claude breaks it into the smallest possible first step and just gets me started. Because that’s literally in the instructions.
Let me be real: it’s duct tape
Some reality: I’ve only spent a week building this. TASKS.md is a markdown file, not Asana. Portfolio TVPI in Airtable is manually updated. The briefing sometimes surfaces garbage. Claude occasionally invents a database field that doesn’t exist.
But that’s the point. It doesn’t need to be perfect. It needs to be better than doing everything manually, and it is. Dramatically.
The rough edges are a feature, not a bug. They keep me honest about what the AI can and can’t do. And they keep the system grounded in tools I can always fall back to.
What’s next
What I described above is the foundation. Here’s where it’s going.
AI deal sourcing. This is the big one. Scrolling Crypto Twitter, on-chain revenue data via Dune, GitHub developer activity monitoring, accelerator batch tracking, governance signals — all of these can feed into a sourcing agent that scores opportunities against our 8 venture themes and 3 liquid strategies. EQT built Motherbrain and sourced $100M+ in investments through AI. With modern agent frameworks, a crypto-native solo GP can build something comparable for a fraction of the cost. Because on-chain data is transparent and queryable in ways TradFi data simply isn’t.
Telegram intelligence. I live in Telegram, every crypto fund manager does. Right now Claude can read my messages. But it can’t organized Folders. Next step: organized monitoring across 50+ channels with automated signal extraction. Morning digest: “Three founders mentioned stablecoin rails. Two alpha groups discussing this DEX. One LP pinged you at 2am.”
Vector memory. Right now the context system is structured markdown. Works great, doesn’t scale. The next evolution is embedding every meeting transcript, research note, and email thread into a searchable semantic store. So Claude doesn’t just know what’s in its current context window — it can recall anything from any past interaction.
That’s the difference between an AI that’s useful today and one that compounds knowledge over time.
The playbook
If you’re building a company right now — fund, startup, agency, whatever — here’s what I’d tell you:
Start with traditional tools. Notion, Airtable, Google Workspace, whatever you want. Things humans can operate directly.
Add a structured context layer. Write down who you are, how you work, what your priorities are, how your systems connect. This sounds basic but it’s the highest-leverage thing you can do. The context file IS the operating system.
Connect everything through AI. MCP, agent frameworks, structured memory. Let the AI traverse your entire operation, not just answer one-off questions.
Keep humans in the loop. Not because AI is bad — because hybrid systems are more robust. The AI handles volume and context-switching. Humans handle judgment and relationships.
And hire AI-native people. Operators who build workflows, not just use features.
I’m Alexander Salnikov, GP at Concentrated Capital. We invest in onchain fintech at the convergence of TradFi and DeFi — stablecoin infrastructure, wallets, DeFi primitives. If you’re building in this space or interested in the hybrid venture + liquid model, reach out: alexander@concentrated.vc
More at concentratedcapital.substack.com